Flow Chart
Plaud AI Workflows enable you to chain multiple AI tasks together. The most common pattern combines audio transcription with data extraction to transform unstructured audio into structured, actionable data.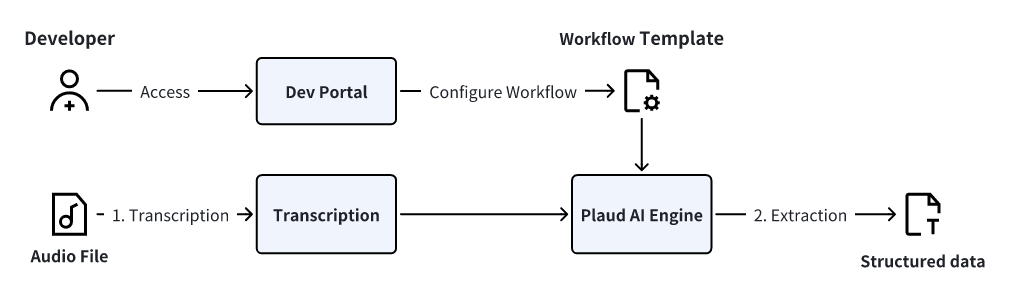
- Transcription: An audio file is processed and converted into a text transcript.
- Template Application: The AI Engine applies the custom Workflow Template containing the rules for data extraction.
- Extraction & Output: The engine processes the transcript according to the template’s rules to produce structured data.
Quick Start
Technical Flow
- Asynchronous Processing: Workflow returns immediately with
workflow_id, tasks execute in background - Chain Execution: Subsequent task only starts after previous task completes
- Webhook Notifications: Real-time status updates sent to your configured webhook endpoints
- Template Integration: Custom template automatically loaded and applied during extraction processing
- Result Storage: All outputs (transcripts, extracted data) stored in secure cloud storage
Prerequisites
1. API Token
Obtain your authentication credentials to securely access the API.
2. Bind Device to User
Associate a device with a user account to enable file uploads.
3. Upload Audio Recording
Upload your audio files to our platform for processing.
4. Create Custom Template
Design a template to define your data extraction rules. (Coming Soon)
Walkthrough
Step 1: Submit AI Workflow
First, submit a workflow that combines audio transcription with a pre-existing custom ETL template.Step 2: Monitor Workflow Progress
You can check the status of your workflow by polling the status endpoint.While polling is useful for quick checks, we strongly recommend using Webhooks for production applications. Webhooks provide real-time status updates to your server without the need for continuous polling.Learn more about configuring webhooks →
Step 3: Retrieve Structured Results
Once the workflow status isSUCCESS, you can fetch the final results.
Step 4: Complete Example
Here’s a complete Python script that handles the entire workflow:complete_workflow_example.py
Common Error Scenarios
| Error Code | HTTP Status | Cause | Solution |
|---|---|---|---|
| WORKFLOW_PARAMS_INVALID | 400 | Missing required parameters or invalid task configuration | Verify file_id, template_id, and task parameters |
| FILE_NOT_FOUND | 404 | Audio file doesn’t exist or not accessible | Ensure file is uploaded and belongs to correct user |
| TEMPLATE_NOT_FOUND | 404 | Invalid template_id provided | Verify template exists and belongs to your client |
| INSUFFICIENT_CREDITS | 402 | Account lacks credits for AI processing | Top up your account credits |
| TASK_PROCESSING_FAILED | 500 | AI processing encountered an error | Check audio quality, try again, or contact support |
Explore More
Custom Templates
Learn to create, manage, and version templates for precise data extraction.
Webhook Events
Receive real-time notifications for workflow and task status updates.